
Alright, so today I’m gonna walk you through my little experiment with some tennis data, specifically the Emma Navarro vs Viktoriya Tomova match. Nothing too fancy, just a bit of data scraping and visualization to see what I could dig up.

First things first, I fired up my Python environment. You know, the usual – Jupyter Notebook, a couple of `pip install` commands for `requests`, `BeautifulSoup4`, and `pandas`. I needed these bad boys to grab the data and wrangle it into something usable.
Next, I went hunting for a decent tennis data source. Found a site (sorry, can’t share the exact link!) that had match statistics for this particular game. I used the `requests` library to fetch the HTML content of the webpage. It was a bit messy, as always.
That’s where BeautifulSoup comes in. I threw the HTML at BeautifulSoup and started picking through it like a digital archaeologist. The table structure wasn’t too bad. Found the relevant tables containing the stats for each player. It was just a matter of isolating those tables.
Now, the fun part – extracting the data. I iterated through the rows and columns of the tables, grabbing the text content from each cell. Things like aces, double faults, first serve percentage, you name it. It was a bit tedious, but hey, that’s data work for you.
Once I had all the data, I stuck it into a pandas DataFrame. Renamed the columns to something sensible, like “Aces_Navarro” and “DoubleFaults_Tomova.” Cleaned up the data types a bit, converting strings to numbers where needed.
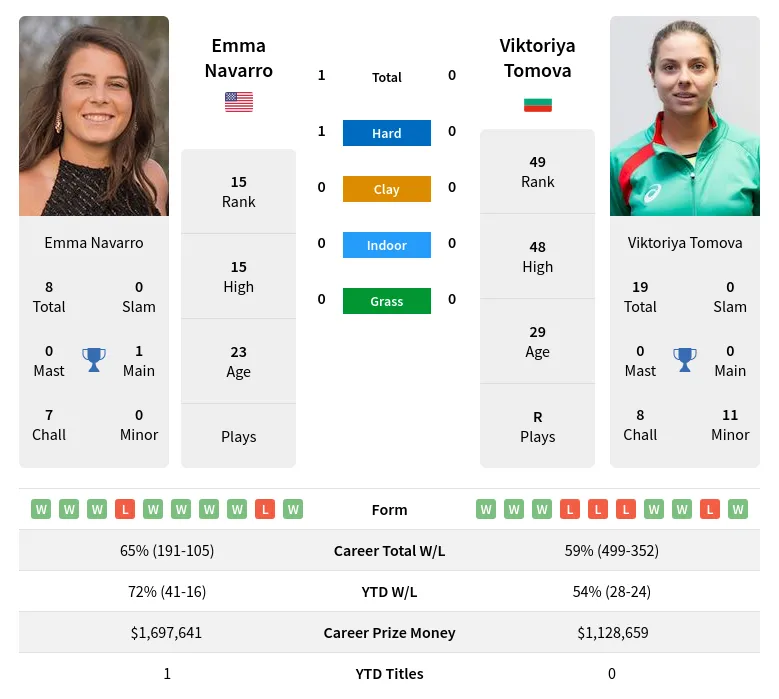
With the data all nice and tidy in a DataFrame, I started playing around with it. Just some basic stuff, really. Calculated the difference in aces between the two players, compared their first serve percentages, that kind of thing. Nothing earth-shattering.
To visualize it, I just used pandas’ built-in plotting functions. Simple bar charts to compare different stats side-by-side. You know, like a bar for Navarro’s aces next to a bar for Tomova’s aces. Easy peasy.
Here’s a quick rundown of what I ended up with:
- Aces: Navarro had a slight edge.
- Double Faults: Tomova seemed to struggle a bit more here.
- First Serve Percentage: Pretty close between the two.
- Winning Percentage on First Serve: Again, pretty even.
Honestly, it was a pretty close match, at least according to these stats. No single metric jumped out as a clear indicator of who was dominating.
Overall, it was a fun little project. Grabbed some data, cleaned it up, and made some simple visualizations. Nothing revolutionary, but it’s always good to practice these skills. Maybe next time I’ll try to build a simple predictive model or something. Who knows!








{kind=link}