
Okay, so I was messing around with some tennis data the other day, and I got curious about the Cincinnati Open prize money. Figured, hey, why not see if I could dig up some info and maybe even do a little analysis? Here’s how it went down.
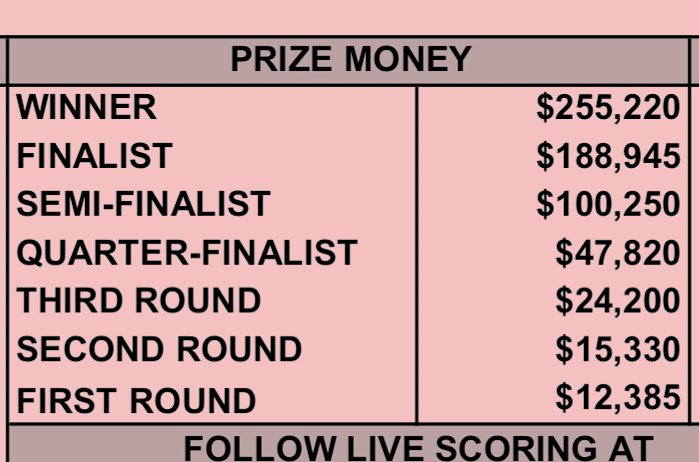
First thing I did was just Google “Cincinnati Open prize money.” Duh, right? But you gotta start somewhere. Scrolled through a bunch of news articles and official tournament sites. It was a bit scattered, but I was able to piece together some of the prize money breakdowns for recent years.
Then I started thinking, “Okay, how can I get this data in a more usable format?” Copy-pasting from websites is a pain. So, I went searching for some tennis data APIs. Found a few options, but most of them required subscriptions or had limited free tiers. I ended up finding some decent datasets on Kaggle – people had already scraped and compiled the data. Score!
Pulled down a couple of those datasets into a Pandas DataFrame. Man, Pandas is a lifesaver. Started cleaning things up. Some of the columns were mislabeled, and there were some missing values to deal with. Nothing too crazy, just the usual data cleaning grind.
The Fun Part: Once the data was reasonably clean, I started doing some basic analysis. I wanted to see how the prize money had changed over the years, specifically for the men’s and women’s singles champions. I grouped the data by year and then calculated the average prize money. Threw it into a quick plot using Matplotlib.
Turns out, the prize money has generally been increasing over time, which isn’t too surprising. But I also wanted to compare the men’s and women’s prize money. I created another plot to visualize the difference. It’s been pretty close in recent years, which is good to see, but there were definitely some discrepancies in the past.

- Initial Search: Google searches to get a general overview.
- Data Acquisition: Found datasets on Kaggle.
- Data Cleaning: Used Pandas to clean and preprocess the data.
- Analysis: Analyzed prize money trends using Pandas and Matplotlib.
After all that, I had a decent understanding of how the Cincinnati Open prize money has evolved. It was a fun little project, and I learned a thing or two about data analysis along the way. Plus, now I have some cool graphs to show off to my tennis-loving friends.
Next steps? I might try to build a small interactive dashboard using Streamlit or something. That would be a cool way to explore the data in more detail. Maybe even try to predict future prize money based on historical trends. Who knows?






{kind=link}