
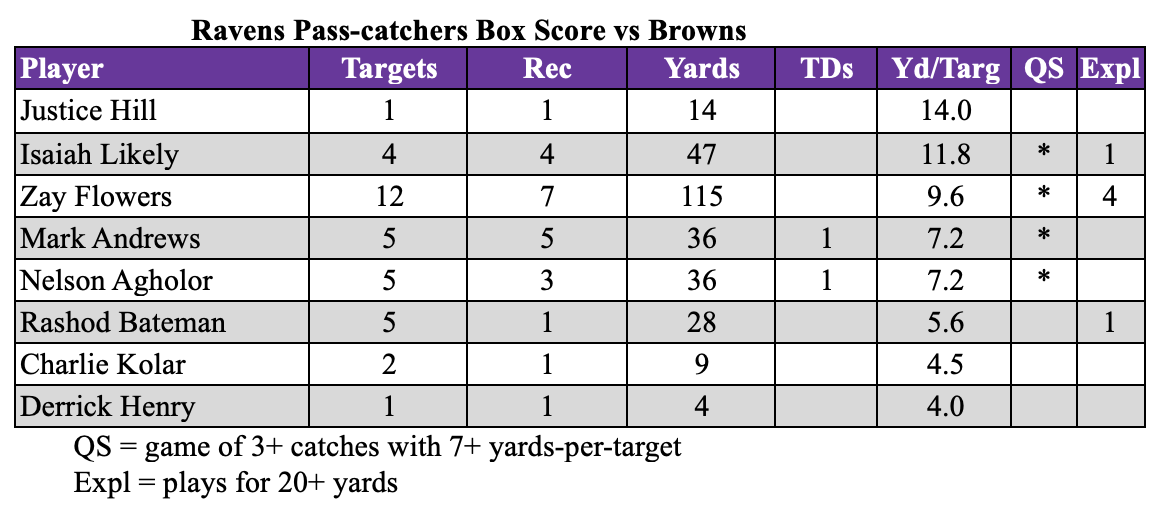
Alright, let’s dive into this whole “ravens box score” thing. It was a bit of a grind, but hey, that’s how we learn, right?

So, I started with the basic idea: I wanted to grab the box score data for Ravens games. I figured it couldn’t be that hard. Famous last words, am I right?
First off, I googled around for APIs. Turns out, there are a bunch of sports data APIs out there, but most of them want you to pay. And, well, I’m cheap. So, I decided to try my hand at web scraping. I know, I know, scraping can be a pain, but I was determined.
I picked a site that looked like it had reasonably well-structured data – ESPN, I think it was. Then I installed the basic tools I needed: Python (obviously), `requests` to grab the HTML, and `BeautifulSoup` to parse it. If you don’t have these things you will need to install them.
pip install requests beautifulsoup4
Next I used `requests` to download the HTML content of a Ravens game’s box score page. It was just one line of code:
response = *(url)
Simple enough.
Then, I initialized `BeautifulSoup` to parse the HTML:
soup = BeautifulSoup(*, ‘*’)
Now the fun began. I had to inspect the HTML source of the webpage and figure out where the actual box score data was located. This involved a LOT of right-clicking, “Inspect Element,” and swearing under my breath. ESPN loves to change their website layout on a whim, so you can’t always rely on consistent class names or IDs.
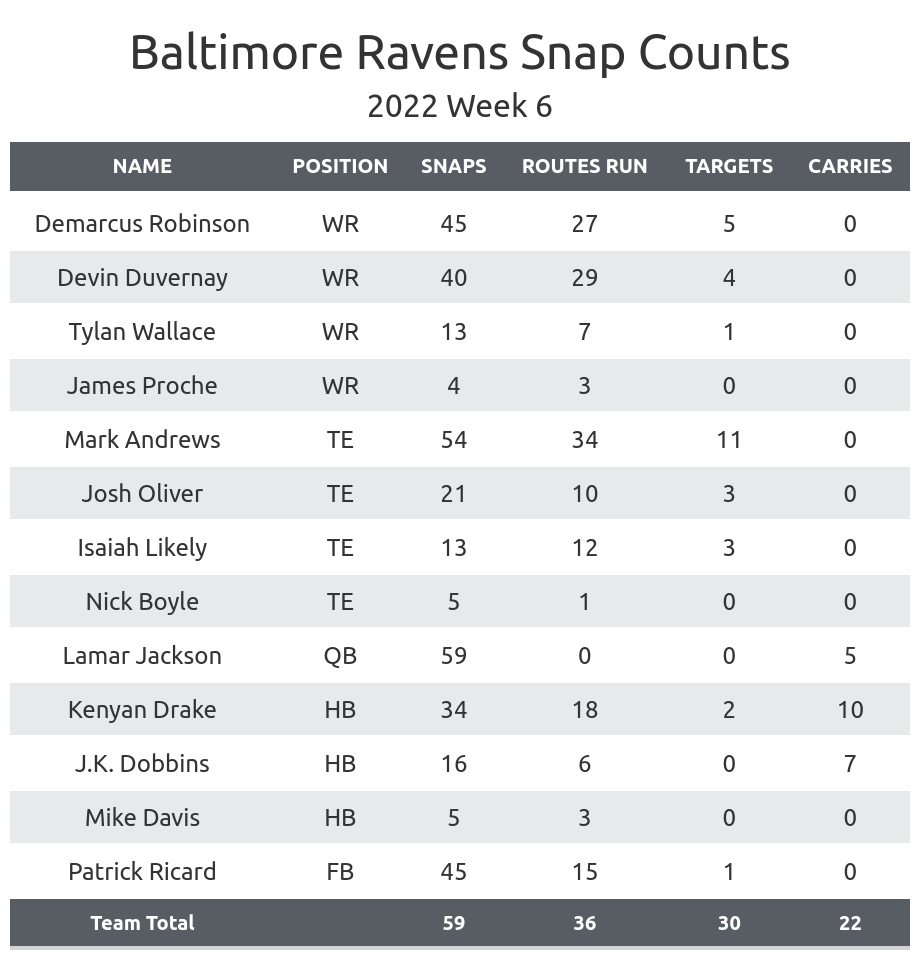
I carefully picked out the HTML tags and CSS classes that contained the data I needed (team names, scores, player stats, etc.). And then, using `BeautifulSoup`’s `find()` and `find_all()` methods, I started extracting the information.
This is where things got messy. ESPN’s HTML structure was… complicated, to say the least. I had to write a bunch of loops and conditional statements to handle different table structures and weird formatting issues. I was using trial and error a lot. Print statements became my best friends. And I made a ton of mistakes along the way.
For example, sometimes a player’s name was in one tag, and their stats were in a completely different tag, separated by a bunch of other HTML elements. Or sometimes, a table row would be missing a cell, throwing off all my indexing. I had to add checks and workarounds to handle all these edge cases.
Once I had all the data, I needed to clean it up. The raw data was full of extra whitespace, special characters, and weird abbreviations. I used Python’s string manipulation methods to remove all the garbage and standardize the formatting.
Finally, I organized the cleaned data into a Python dictionary. This dictionary contained all the key information from the box score: team names, scores, player stats, and so on. The dictionary looks like this:

- team1_name:”Baltimore Ravens”
- team2_name: “Opponent Team”
- team1_score: 24
- team2_score: 10
- team1_players:[“player_name_1”, “player_name_2”, …]
- team2_players: [“player_name_1”, “player_name_2”, …]
Then I wrote some functions to print out the box score in a nice, readable format. It wasn’t pretty, but it worked.
The whole process took me way longer than I expected. I ran into a bunch of unexpected issues, and I had to debug my code over and over again. But in the end, I got it working. I could scrape the box score data for Ravens games and display it in a useful way.
It wasn’t perfect, but it was mine. And I learned a lot about web scraping, HTML parsing, and data manipulation along the way. Plus, now I have a cool little script that I can use to keep track of the Ravens’ stats. Not bad for a weekend project!








{kind=link}